2020. 6. 16. 16:55ㆍ강의/스프링 부트 개념과 활용
1. ORM과 JPA
스프링 부트에 관심이 있다면 한 번쯤 ORM과 JPA에 대해 들어본 적이 있을 것이다.
ORM은 Object-Relational Mapping의 약자이다. 말 그대로 Object와 Relational을 맵핑할 때 발생하는 개념적 불일치를 해결하는 프레임워크이다. 예를 들어 어떤 클래스는 여러 가지 멤버 변수를 가질 수 있는 데에 비해 테이블은 테이블과 칼럼만을 가지고 있다. 그렇다면 어떻게 객체의 다양한 항목을 테이블에 맵핑시킬 수 있을 것인가? 또한, 객체들 간에는 상속이라는 개념이 존재하지만 테이블 간에는 이러한 개념이 존재하지 않는데 어떻게 맵핑시킬 것인가? 이러한 문제들을 해결해 주는 것이 ORM이다.
JPA는 ORM을 위한 자바 표준이다. JPA는 하이버네이트를 기반으로 만들어 졌다. 따라서 경우에 따라서는 하이버네이트 설정을 해야 한다. 스프링 데이터 JPA는 이러한 JPA를 아주 쉽게 사용할 수 있게끔 스프링 데이터로 추상화시켜놓은 것이다.
이러한 스프링 데이터 JPA를 사용한다는 것은 결국 JPA를 사용하는 것이고 이것은 하이버 네이트를 사용하는 것을 의미하며 결론적으로 DataSource를 사용하는 것을 의미한다.
2. 스프링 데이터 JPA
스프링 데이터 JPA를 사용하는 예제를 만들어 보자.
1) 스프링 데이터 JPA를 사용하려면 @Entity클래스를 먼저 만들어야 한다.

@Entity를 통해 이 클래스를 맵핑할 수 있다. 각 멤버 변수에 대한 getter와 setter, equals()와 hashcode()를 만들어 준다.
(lombok을 이용하여 이러한 과정을 쉽게 하는 방법이 있는데 다음에 정리해 보아야겠다.)
@Entity가 붙은 클래스는 JPA가 관리하는 클래스를 의미하며 해당 클래스를 엔티티라고 부른다.
JPA를 사용하여 테이블과 맵핑할 클래스는 반드시 이 @Entity를 붙여주어야 한다.
2) JpaRepository를 확장한 Repository를 인터페이스로 만든다.

JpaRepository를 상속받으면 기본적인 CRUD기능을 사용할 수 있게 된다.
3) Repository에 대한 테스트 코드를 작성한다.
이때 슬라이싱 테스트를 만드는데, 슬라이싱 테스트란 해당 클래스와 관련된 빈들만 등록을 해서 테스트를 하는 것이다. 여기서는 @DataJpaTest 어노테이션을 이용해 슬라이싱 테스트로 만들었다.

이렇게 슬라이싱 테스트를 할 때는 인메모리 데이터베이스가 반드시 필요하다.
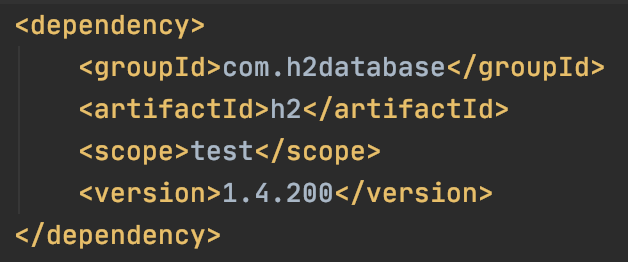
따라서 저번 정리때 공부했던 h2 의존성을 scope test로 하여 추가해준다.
이후 테스트코드를 실행하면 잘 통과되는 것을 확인할 수 있다.
4) mysql 연동
테스트 코드는 잘 통과되지만 애플리케이션이 동작하기 위해서는 데이터베이스가 연동되어야 한다. 위에서 인메모리 데이터의 scope을 test로 한정지 었기 때문에 그냥 실행하면 데이터베이스를 찾지 못하여 오류가 뜬다.
mysql연동은 지난 정리에서 했던대로 진행하면 된다. 잘 연동되었다면 애플리케이션도 오류 없이 잘 실행된다.

위와 같은 과정을 슬라이싱 테스트로 진행하지 않으면 테스트 코드에서 본 코드의 mysql을 빈으로 등록하여 mysql 데이터베이스에 접근하게 된다. 이렇게 하면 테스트 코드로 인해 본 코드의 데이터베이스가 변경될 위험이 있으므로, 인메모리 데이터베이스를 이용하는 슬라이싱 테스트로 코드를 작성하는 것이 바람직하겠다. (이렇게 하면 테스트 속도도 훨씬 빨라진다.)
다른 방법으로는 테스트에서 사용될 properties를 만들고, 테스트용으로 사용할 데이터베이스도 만들어 설정해주는 방법이 있지만 위의 방법이 훨씬 간단하다.
이번 정리에서는 슬라이싱 테스트를 사용하는 이유를 제대로 확인할 수 있었다.
3. 데이터베이스 초기화
JPA를 이용하여 데이터베이스의 초기 상태를 설정할 수 있다.
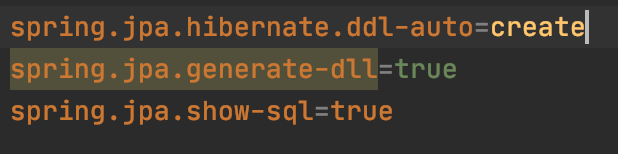
먼저, application.properties에 spring.jpa.hibernate.ddl-auto의 값으로 update, create, create-drop 등을 설정해주면 스키마가 자동으로 생성된다. 이후 spring.jpa.generate-dll=true을 추가해주면 작동된다.
spring.jpa.hibernate.ddl-auto의 값을 update로 할 경우 기존의 칼럼을 삭제하지 않고 새로 만들지만, create와 create-drop은 기존의 테이블을 없앤 후 새로 만든다.

account의 멤버 변수에 맞게 테이블이 자동으로 초기화되어 생성된 것을 볼 수 있다.
JPA가 아닌 SQL 스크립트를 통해 초기화할 수도 있는데 schema.sql 파일에 초기화 시 동작할 쿼리문들을 넣는 것이다.(위치는 resource 밑에!)
4. 데이터베이스 마이그레이션
CRUD(Create, Read, Update, Delete)를 잘 수행하려면, 데이터 베이스 테이블 스키마가 잘 정의되어 있어야 한다. 마이그레이션이란,
한 운영환경으로부터 다른 운영환경으로 옮기는 작업을 뜻한다. (예를 들어, 윈도에서 리눅스) 하드웨어, 소프트웨어, 네트워크 등 넓은 범위에서 마이그레이션의 개념이 사용되고 있다. 데이터베이스에서 데이터 마이그레이션이란, 데이터 베이스 스키마의 버전을 관리하기 위한 하나의 방법(데이터 전환)이다. 데이터베이스 마이그레이션은, 개별 SQL 파일을 MySQL 콘솔 등에서 직접 실행하지 않고, 프레임워크의 특정 명령어를 통해 실행하고 이 결과를 별도의 테이블에 버전 관리를 하는 기법이기도 하다.
사용하는 툴은 Flyway와 Liquibase가 대표적인데, 이 강의에서는 Flyway를 사용하였다.
1) 의존성 추가
역시나 무엇인가 사용하려면 의존성을 추가해야 한다.

2) resource밑에 db.migration 폴더를 만들어주고 안에 sql파일을 위치시킨다.

이때 db/migration 폴더명은 정해진 값이므로 다른 이름으로 하면 안 된다.
3) 마이그레이션 파일
마이그레이션 파일 이름은 아래와 같은 형식으로 지어주어야 한다.
- V숫자__이름.sql
- V는 꼭 대문자로.
- 숫자는 순차적으로 (타임스탬프 권장)
- 숫자와 이름 사이에 언더바 두 개.
- 이름은 가능한 서술적으로.
'강의 > 스프링 부트 개념과 활용' 카테고리의 다른 글
| [인프런 강의] 스프링 부트 개념과 활용 - 11 (0) | 2020.06.22 |
|---|---|
| [인프런 강의] 스프링 부트 개념과 활용 - 9 (0) | 2020.06.10 |
| [인프런 강의] 스프링 부트 개념과 활용 - 8 (0) | 2020.06.09 |
| [인프런 강의] 스프링 부트 개념과 활용 - 7 (0) | 2020.06.04 |
| [인프런 강의] 스프링 부트 개념과 활용 - 6 (0) | 2020.06.04 |